Polygon zkevm 架构调研
概述
官网:https://docs.polygon.technology/zkEVM/architecture/
Hermes1.0是以太坊第一个去中心化的zkRollup,于2021年3月上线,可实现2000tps,足以满足ETH及ERC-20 token的转账合约,Hermes1.0并不是与EVM完全兼容的。
Hermes2.0的定位是zkEVM,相较于Hermes 1.0, Hermes 2.0最主要的功能就是提供智能合约的支持,Hermez 2.0 zkEVM与以太坊主网EVMs兼容。可将以太坊主网的智能合约部署在Polygon zkEVM中,可共用以太坊现有的开发工具和套件。
Polygon zkEVM整体架构
官方架构图:
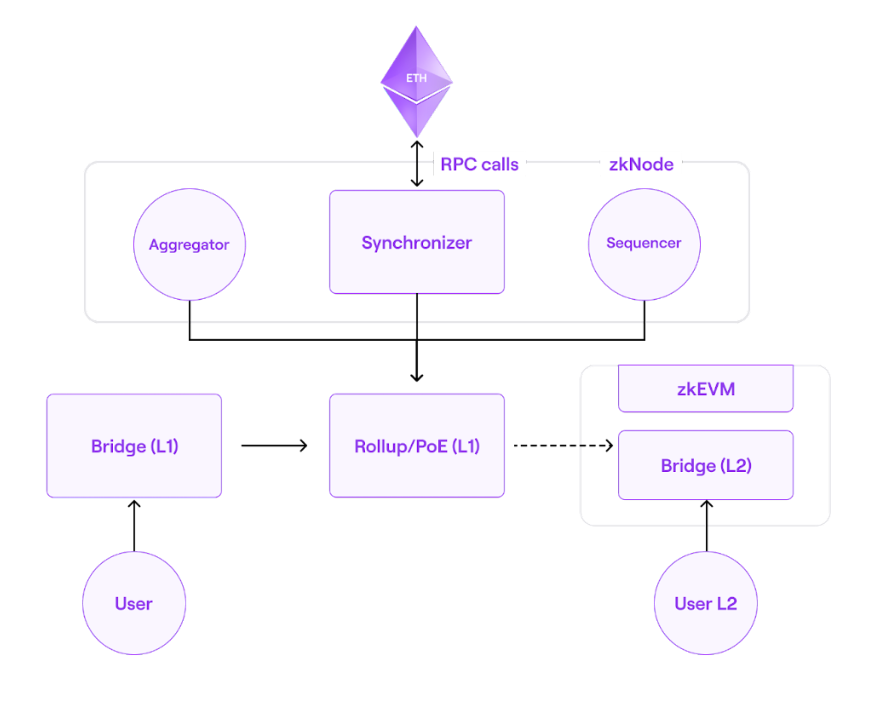
(感觉这个架构图描述不是特别清晰,只是知道有哪些组件,组件之间的层次并不是很清晰)。
Polygon zkEVM中包含的主要组件有:
- 共识合约(POE共识,PolygonZkEVM.sol)
- zkNode:
- 同步器(Synchronizer)
- 排序器(Sequencers)
- 聚合器(Aggregators)
- RPC
- zk验证器(zkProver)
- zkEVM Bridge(跨链桥)
zkNode
zkNode是运行zkEvm节点所需要的软件,它是同步并了解Polygon zkEVM状态所需要的客户端。
改变L2状态及最终结果确认的主要参与者是:受信任的Sequencer和受信任的Aggregator。
zkNode架构
zkNode官方架构(来自:https://docs.polygon.technology/zkEVM/architecture/zknode/和https://github.com/0xPolygonHermez/zkevm-node):
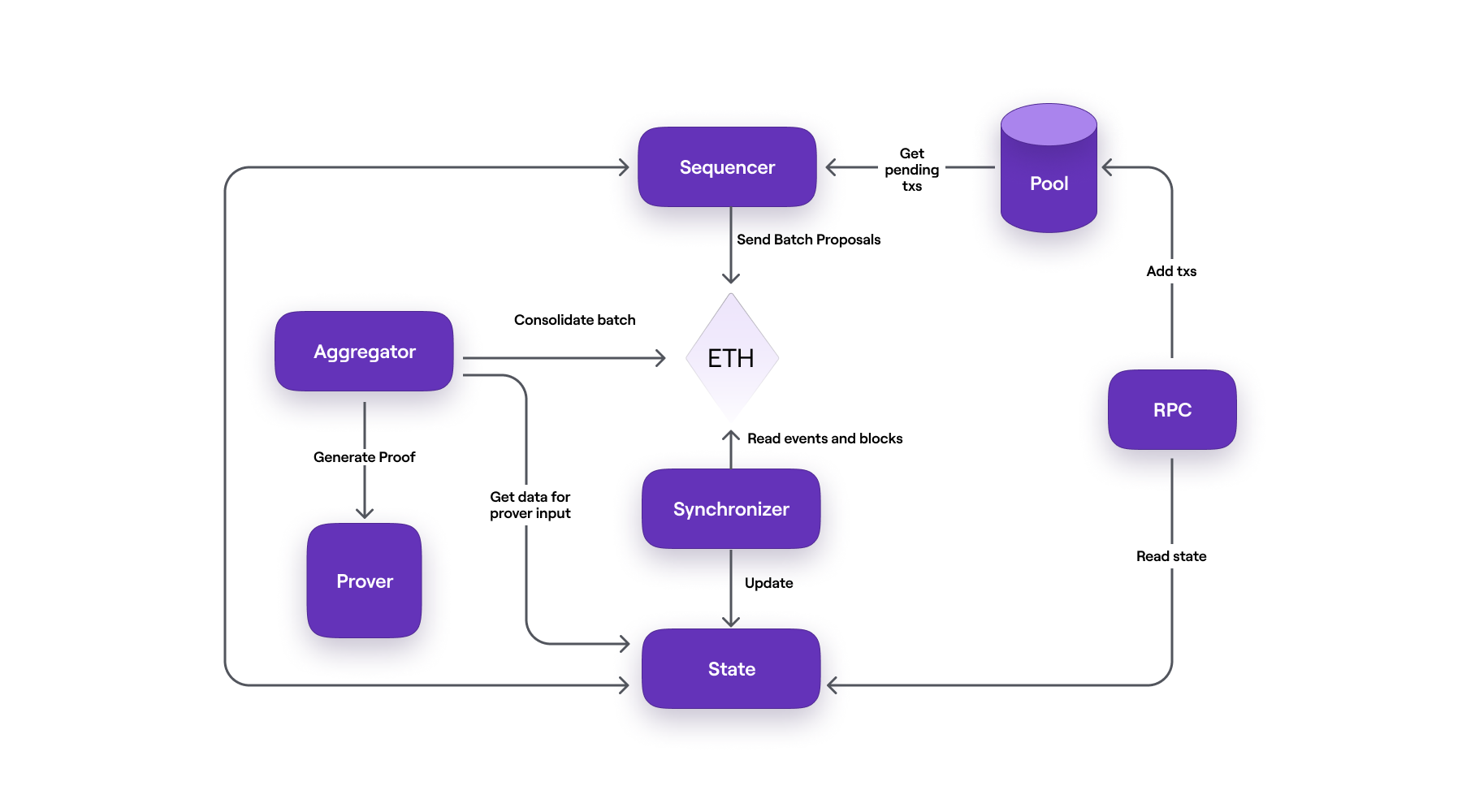
(上图逻辑看着不是很清晰,看完还是有点不太理解流程执行顺序是什么)。
zkEVM组件列表如下:
- Pool DB:存储用户提交的交易,交易被保存在Pool中,等待Sequencer将交易打包成batch。
- Sequencer:是一个节点,负责从PoolDb中获取交易,检查交易是否有效,然后将有效交易打包成batch。Sequencer将所有的batch提交给L1,由L1对batch进行排序。这样,已排序的batch旧包含在了L1的状态中。
- Aggregator:是另外一个节点,从L1中获取到batch,并为batch生成证明,然后提交到L1进行有效性验证。
- Prover:用于为batch计算ZK证明,并将多个batch的证明聚合成一个证明,作为有效性证明进行发布。
- Synchronizer:通过Etherman从以太坊获取数据来更新状态数据库。
- Etherman是一个低级的组件,它实现了与L1网络和智能合约交互的方法。
- State DB:用于持久化存储状态数据(不是Merkle树)的数据库。
zkNode中的角色
来自:https://docs.polygon.technology/zkEVM/architecture/zknode/
zkNode软件支持多种角色,每个角色需要不同的服务才能进行工作,大多数的服务可以在不同的实例中运行,但是JsonRpc可以在多个实例中运行。
RPC endpoints
任何用户都可以作为 RPC 节点参与此角色。
所需的服务和组件:
- JSON RPC:可以在单独的实例上运行,并且可以有多个实例。
- 同步器:可以在单独的实例上运行的单个实例。
- Executor & Merkletree:可以在单独的实例上运行的服务。
- 状态数据库:可以在单独的实例上运行的 Postgres SQL。
Trusted sequencer
此角色只能由单个实体执行。这是在智能合约中强制执行的,因为可信排序器的相关方法只能由特定私钥的所有者执行(这个还有点不太懂)。
所需的服务和组件:
- JSON RPC:可以在单独的实例上运行,并且可以有多个实例。
- Sequencer和Synchronizer:需要将它们一起运行的单个实例。
- Executor & Merkletree:可以在单独的实例上运行的服务。
- Pool DB:可以在单独的实例上运行的 Postgres SQL。
- State DB:可以在单独的实例上运行的 Postgres SQL。
Aggregator
这个角色可以由任何人来扮演。
所需的服务和组件:
- Synchronizer:可以在单独的实例上运行的单个实例。
- Executor & Merkletree:可以在单独的实例上运行的服务。
- State DB:可以在单独的实例上运行的 Postgres SQL。
- Aggregator:可以在单独的实例上运行的单个实例。
- Prover:可以在单独的实例上运行的单个实例。
- Executor:可以在单独的实例上运行的单个实例。
建议证明者在单独的实例上运行,因为它有重要的硬件要求。
疑问
Aggregator怎么获取batches
不理解的问题,Aggregator怎么获取batches的?是从State直接获取的数据,还是直接从L1获取?
上面的图中Aggregator是直接从State中获取的Prover所需要的数据的,但是官方有一张图,如下(来自:https://docs.polygon.technology/zkEVM/architecture/protocol/state-management/#trustless-l2-state-management):
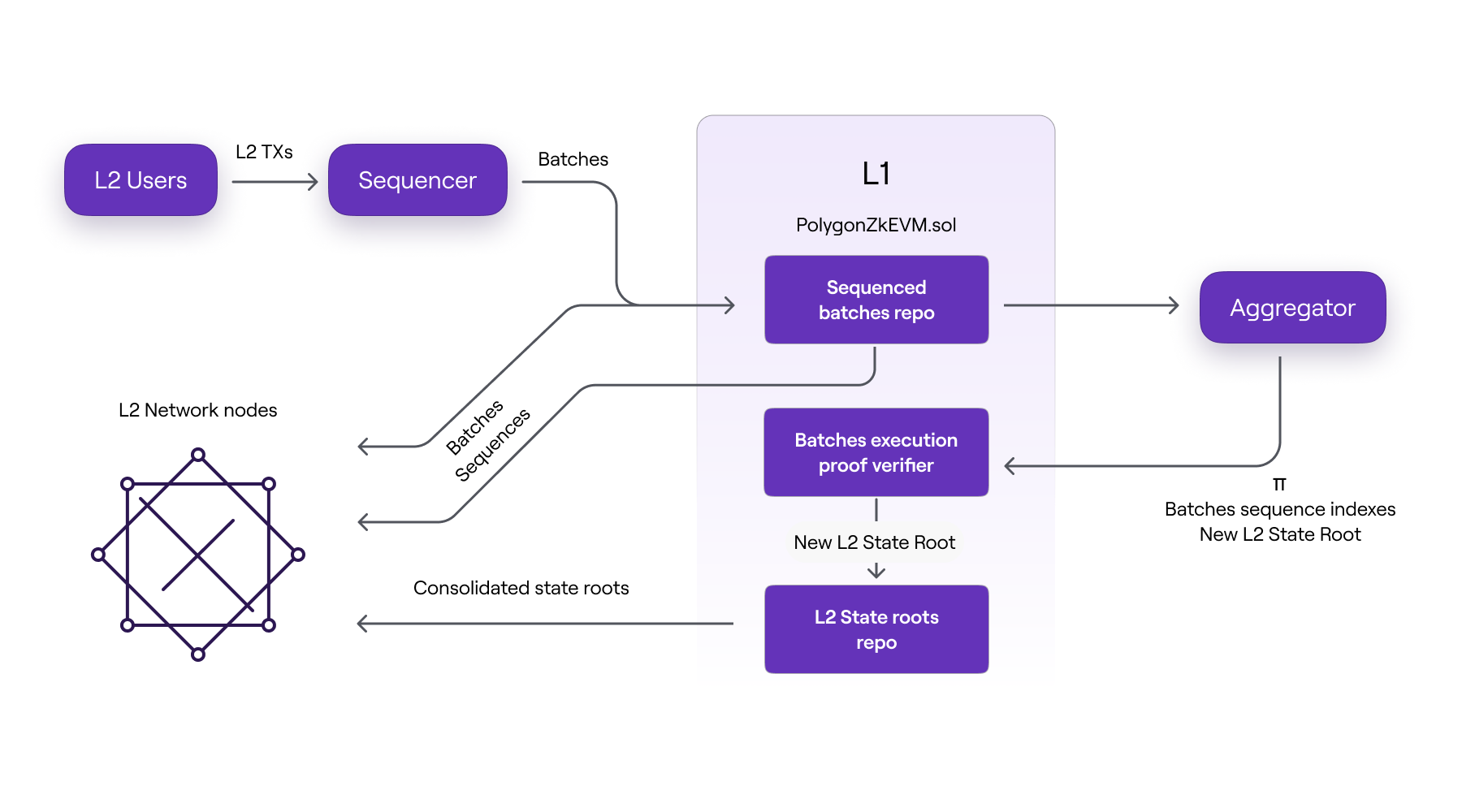
Aggregator从L1的PolygonZkEVM合约中直接获取batches, 然后利用Prover做证明的。
所以Aggregator怎么获取batches的?是从State直接获取的数据,还是直接从L1获取?
可能是这样的Aggregator有自己的Synchronizer,也有自己的State,Aggregator的Synchronizer从L1拉取batches,然后村存储在Aggregator的Statedb中,Aggregator在计算ZK Proof时,就会从State请求获取prover所需要的数据。
因为Aggregator需要Synchronizer和StateDB,参考zkNode中的角色。
那么Synchronizer和State是Sequencer和Aggregator共用的吗??
这个不太清楚,zkNode中的角色中介绍有,Aggregator需要Synchronizer和StateDB, Sequencery要有自己的ynchronizer和StateDB。
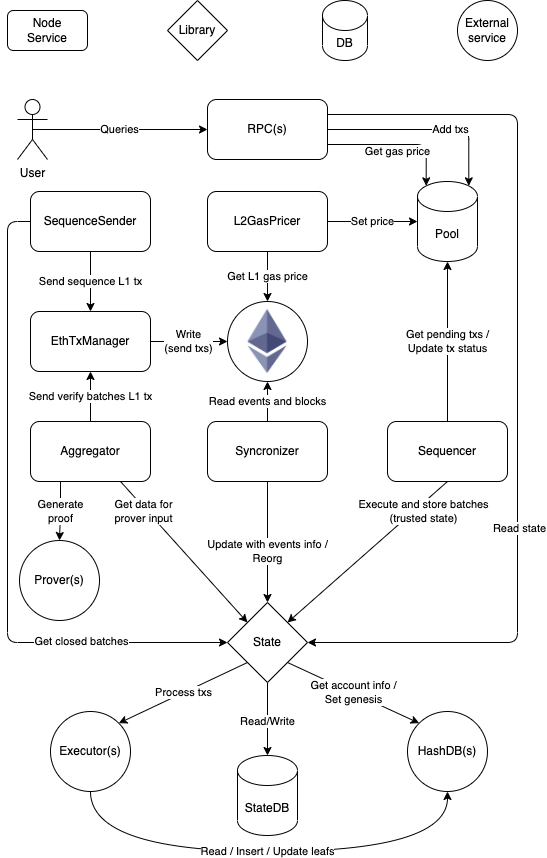
交易流程
根据自己的理解画的图(State和StateDB这一块还不是很清楚), 整体通过Synchronizer来将各个模块进行解耦合。
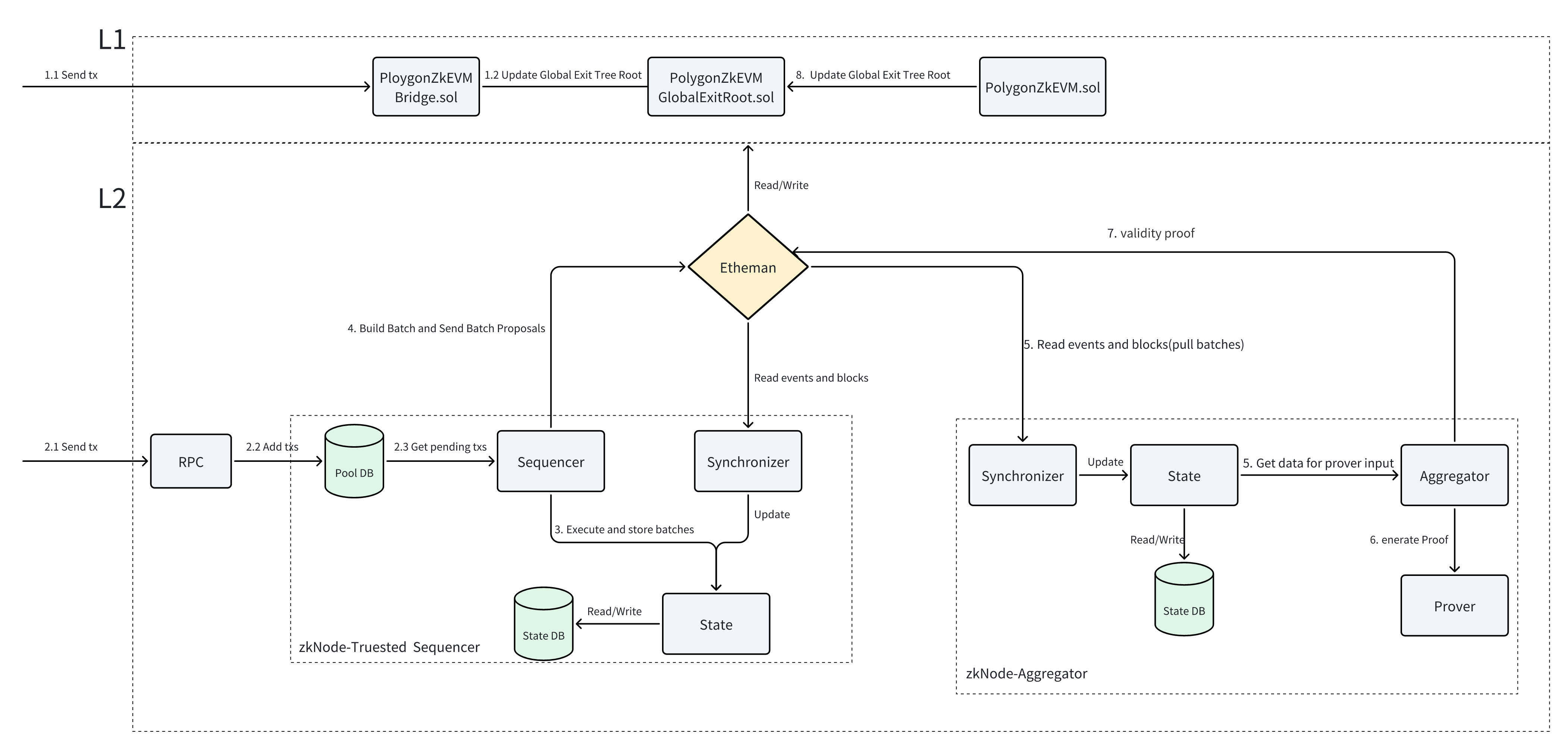
大概流程:
主要分为三个步骤:
- Sequencer将多个用户的交易打包成Batch提交到L1的合约上(Data Avaliability)。
- Prover为每笔交易生成有效性证明(validity proof),并将多个交易的有效性证明聚合成一个有效性证明。
- Aggregator提交聚合了多个交易的有效性证明(validity proof)到L1的合约上。
Sequencer将交易提交到L1
用户将交易发送给Sequencer,Sequencer会在本地按照收到交易的快慢顺序进行处理(FRFS),当Sequencer在本地将交易执行成功之后,如果用户相信Sequencer是诚实的,那么他就可以认为这个时候的交易已经达成finality。
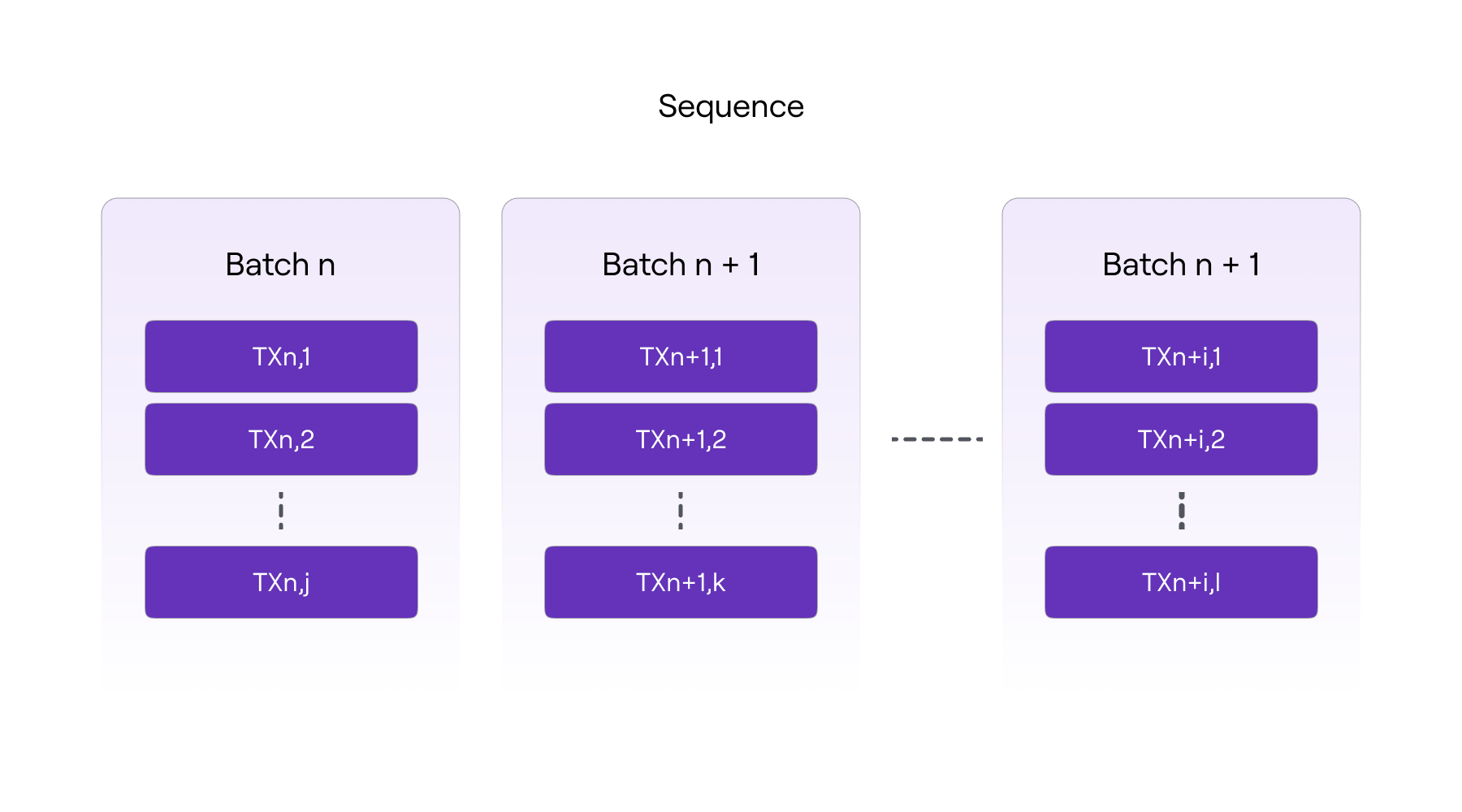
Sequencer会将多笔交易打包进一个Batch里面(目前是一个Batch里面只包含一个交易),然后收集到多个Batches之后,通过L1上的
PolygonZkEVM.sol的sequenceBatch()函数将多个Batch一起发送到L1交易的calldata上。当
PolygonZKEVM.sol收到Sequencer提供的Batches后,会依次在合约内计算每个Batch的哈希,然后在后一个Batch里面记录前一个Batch的哈希(和Block类似),如下图。Batch里面的交易也是确定的,所以当Batch的顺序确认之后,我们认为所有被包含在Batch提交到L1的PolygonZkEVM合约的交易的顺序都是确认的。
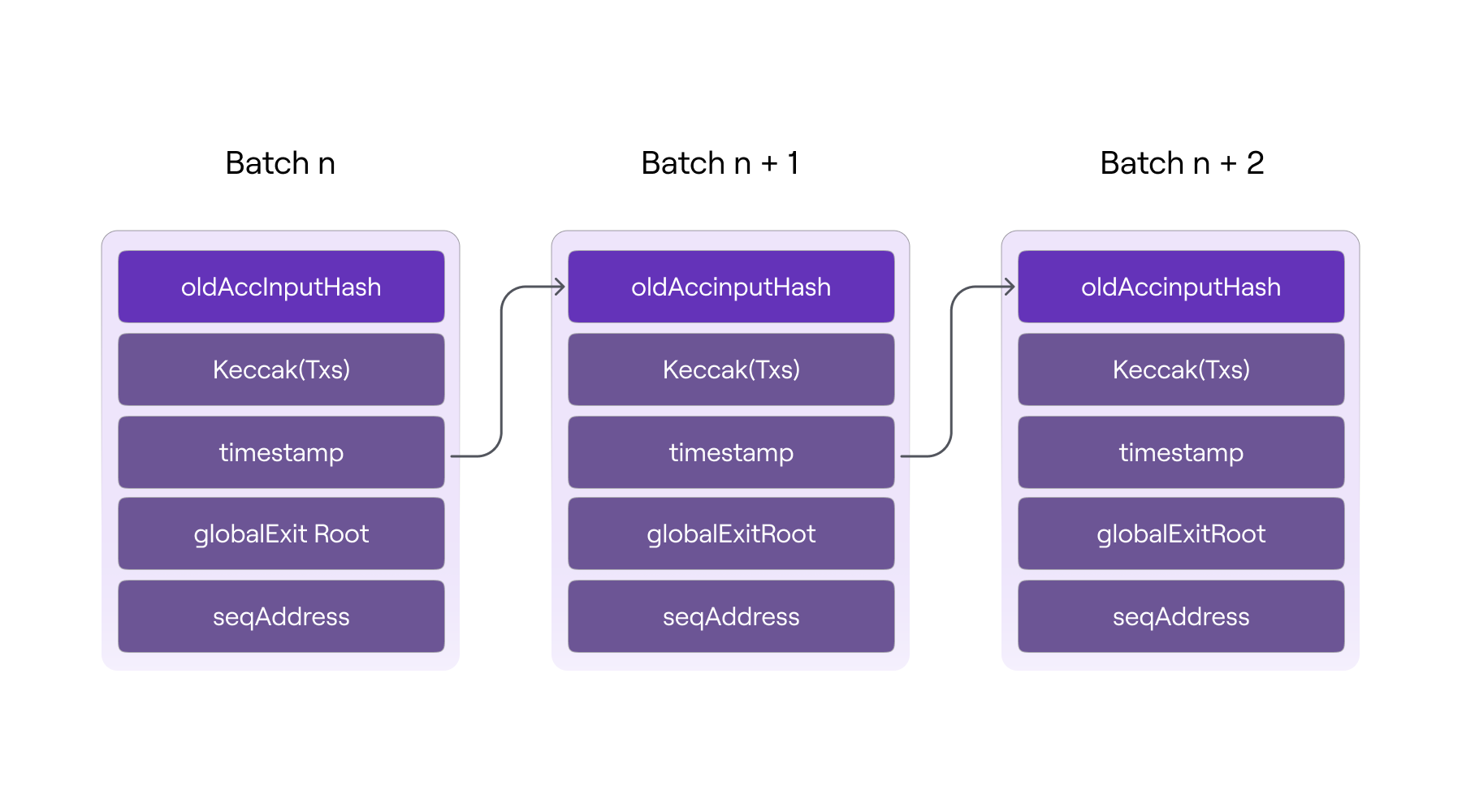
此阶段,将L1充当Rollup DA层和完成交易排序。
Aggregator生成validity proof
- 当Aggregator监听到L1的
PolygonZkEVM.sol合约中已经有新的Batch被成功提交后,它会把这些Batch同步到自己的节点里,然后给zkProver发送这些交易。 - zkProver接收到这些交易之后会并行的为每笔交易生成有效性证明(validity proof),然后再将多个Batch包含的交易的validity proof再聚合成一个有效性证明(validity proof)
- zkProver将聚合多个交易的validity proof发送给Aggregator
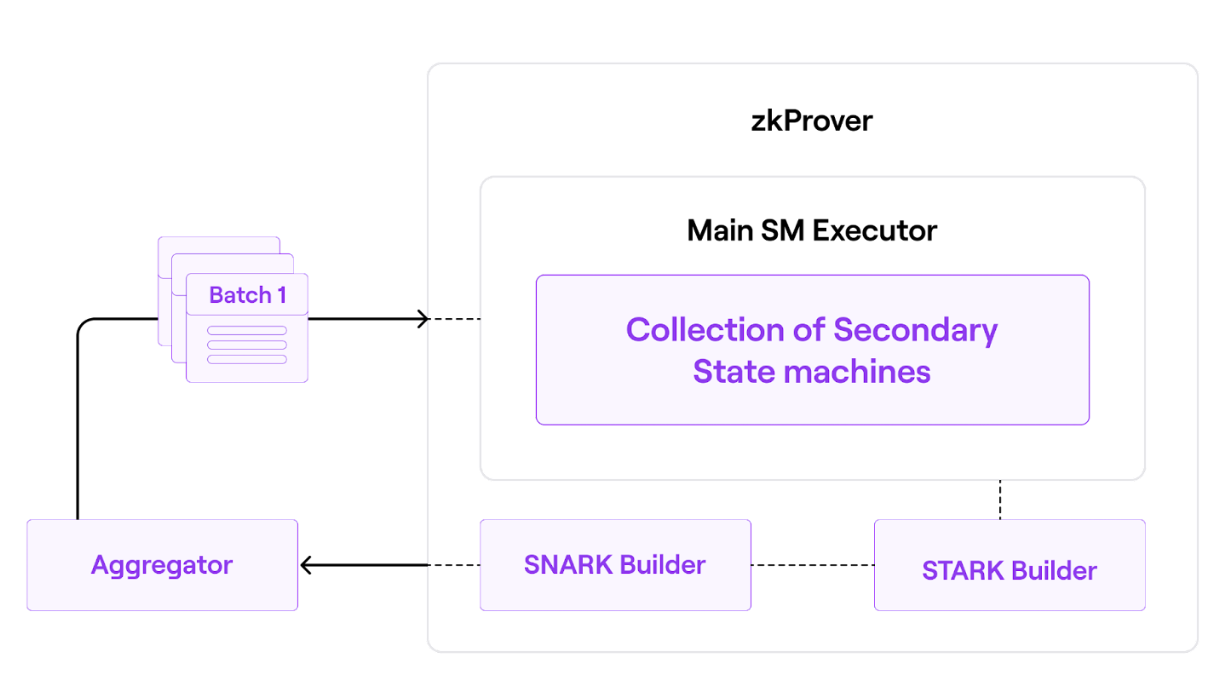
Aggregator提交聚合证明到L1
- Aggregator会讲聚合后到有效性证明(validity proof)以及对应的这些Batch执行后的状态一起提交到L1的
PolygonZkevm.sol合约内(调用trustedVerifyBatches方法)。
三种Finality
可以认为目前整个网络存在三种不同程度的Finality,给它们命名成Sequencer Finality, DA Finality和Verified Finality。
Sequecer Finality,也将这种Finality称为Soft Finality,Polygon中也叫做Sequenecer Finality更为合适,因为这是Single Sequencer 给的状态承诺。
Sequencer接受到用户交易之后,执行后给出的状态,这是最不安全的状态;但是在目前官方Single Sequencer的场景下,却可以在保证安全的同时带来极致的用户体验。在目前Single Sequencer的Rollup网络中,基本上都可以体验到即时确认的快乐。不过,Single Sequencer最大的风险就是Sequencer宕机,这会导致整个L2网络基本瘫痪,不过由于DA层是位于以太坊上的,依然可以在之后部分恢复L2网络宕机前的状态;不过那部分来不及发送到L1的L2交易将无法被恢复。
DA Finality,代表这些交易已经被提交到L1的DA层合约上,此时交易顺序也被确定了。
Trusted Sequencer已经调用
sequenceBatch将交易发送到L1上,在这种情况下,交易已经被DA层包含;在Polygon的设计中, 由于Single Trusted Sequencer的原因,所以可以确保上传到L1合约上进行DA的交易都是有效交易。我们可以认为当一笔交易被Trusted Sequencer 上传到L1合约中的时候, 这个时候它已经被rollup网络承认了,并且在之后Aggregator会提供validity proof让这笔交易真正无法被revert(除非L1 reorg)。Verified Finality,指的是这笔交易已经通过validity proof的验证了,属于真正的Finality,也叫做Hard Finality。
当Aggregator为一批上传到DA层的交易提供的validity proof被合约验证通过的时候,这个时候我们认为这些交易已经无法被revert了(除非L1 reorg)。目前提交到DA层的交易到验证validity proof的通过的时间是30分钟,同时Aggregator也可以通过提供validity proof从而获得足够的Matic报酬。
跨链
Polygon zkEVM在L1和L2上分别维护了一颗Exit Tree, 名字分别为L1 Exit Merkel tree和L2 Exit Merkel tree。为了更好的管理这两棵树,Polygon zkEVM把这两棵树结合在了一起,如下:
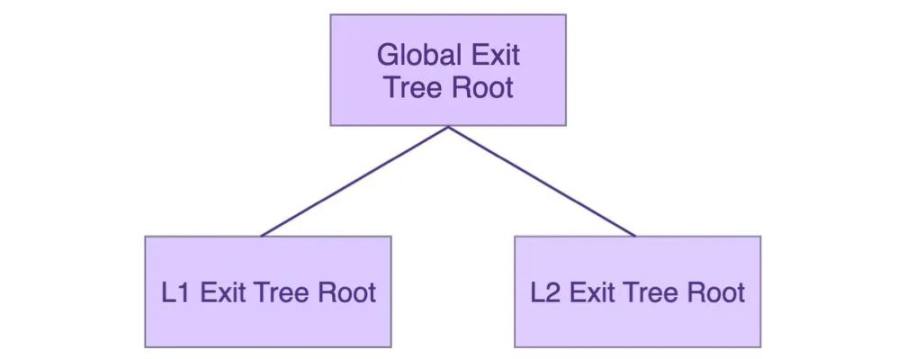
即把 L1 Exit Tree Root 作为 Global Exit Tree 的左叶子节点,把 L2 Exit Tree Root 作为 Global Exit Tree 的右叶子节点。不过需要注意这里 L1 Tree Root 和 L2 Tree Root 是 Sparse Merkle Tree(SMT),而 Global Exit Tree 是 Binary Merkle Tree。
在 Polygon zkEVM 的合约设计中,还是尽可能的将 Bridge 和 Consensus 合约尽可能的解耦。目前其在 L1 部署的合约主要分为 3 个(3个合约是独立的没有继承关系),如下图所示:
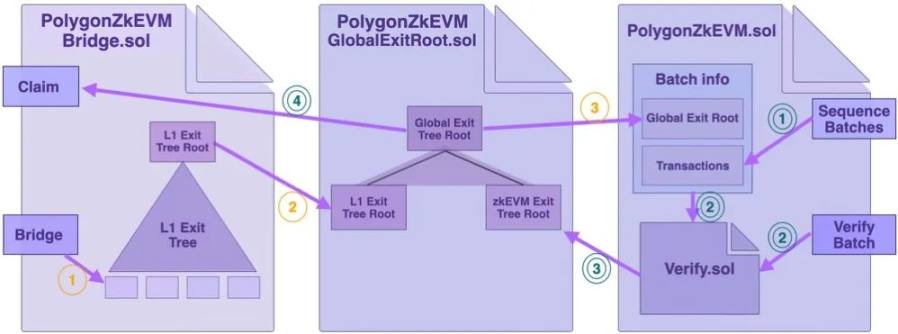
- PolygonZkEVMBridge.sol:跨链桥合约,当用户在源链发起链交易时,会调用
bridgeAsset()方法,或者在目标链调用该合约的claimAsset()方法获得对应链的资产。 - PolygonZkEVMGlobalExitRoot.sol: 用于管理ExitTree的合约,PolygonZkEVMBridge.sol和PolygonZkEVM.sol都会调用PolygonZkEVMGlobalExitRoot.sol来更新Global Exit Tree Root。
- PolygonZkEVM.sol:共识合约,主要用于上传Batch和验证validity proof
L1--->L2
L1到L2的跨链流程对应上图的橙色表示。
- 用户先调用部署在L1上的PolygonZkEVMBridge.sol的
bridgeAsset()方法,这个方法会将当前跨链的metadata添加到L1 Exit Tree中并更新L1 Exit Tree Root。 - 然后调用更新PolygonZkEVMGlobalExitRoot.sol合约中的
Global Exit Tree Root。 - L2有一个Global Exit Root Manager的角色监听发现L1的L1 Tree Root和Global Exit Tree Root都更新之后,会把这个新的Global Exit Tree Root更新到L2的zkEVM中。
- 此时用户就可以在L2的PolygonZkEVMBridge.sol合约中调用
claimAsset()方法进行取款(合约会验证用户提供的Merkel Path是否和当前的Tree Root匹配)。 - 将会在下次调用PolygonZkEVM.sol时的
sequenceBatch()方法的时候,每一个Batch都需要一个有效的Global Exit Tree Root或者一个Empty Root,当这个Global Exit Tree Root结合后续提交的validity proof被验证通过的时候(证明Global Exit Root Manager同步到L2的Global Exit Tree Root是正确的),这个时候才可以认为整个跨链流程已完结。
POE(Proof-0f-Efficiency)
概述
主要用于对交易进行排序,Sequencer可能有多个,每一个Sequencer将交易的batch提交的PoE合约,合约对交易进行排序,即当前的Batch中会包含上一个Batch的hash(类似于L1的block),这样的Batch的顺序就被确定了,Batch的顺序确定也意味着交易的顺序被确定。
Hermez是被设计为去中心化的,不同于Hermez 1.0中使用的PoD(Proof-of-Donation)共识算法,Hermez 2.0采用的是PoE(Proof-of-Effciency)共识。
PoE共识算法主要分为2步,可由不同的参与者完成:
- 第一步的参与者为Sequencer,Sequencer负责将L2的交易打包为batches并添加到L1的PoE智能合约中,合约中对batches进行排序,Sequencer是存在多个的,任何人都可以成为Sequencer。
- 第二步的参与者为Aggregator,Aggregator之间是竞争的,负责检查transaction batches的有效性,并提供validity proofs,Aggregator是多个,任何人都可以参与。
PoE智能合约中有2个基本接口:
sendBatch:用于接收Sequencer的batches,进行batch排序validateBatch:用于接收Aggregator的validity proof,进行validate batches
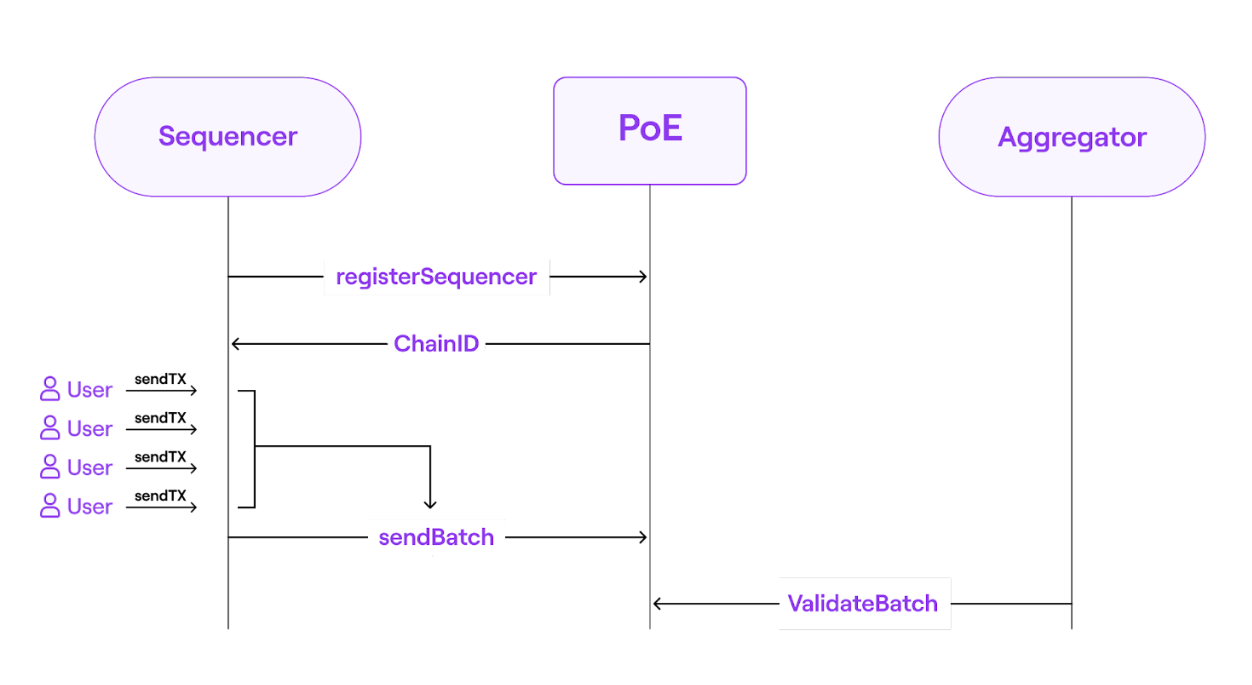
PoE共识
激励机制
疑问:
Single Sequencer和Trusted Sequencer?
StateDB?
参考
官网:https://docs.polygon.technology/zkEVM/architecture/
详解 Polygon zkEVM 的整体架构和交易执行流程: https://learnblockchain.cn/article/5636, https://learnblockchain.cn/article/5647
技术详解 Polygon zkEVM Bridge 和 Sequencer 框架: https://learnblockchain.cn/article/5487
Polygon zkEVM架构: https://learnblockchain.cn/article/5487
CSDN大佬Polygon解析系列:https://blog.csdn.net/mutourend/article/details/125971262