EthStorage
概述
问题出现原因
2023年10月22日,著名的 Go-Ethereum(Geth)开发负责人 Péter Szilágyi 在 Twitter 上表达了他对以太坊数据存储方案的担忧。他指出,虽然 Geth 客户端保留了所有历史数据,但 Nethermind 和 Besu 等其他类型的以太坊客户端,可以配置删除某些以太坊历史数据(例如历史区块)。这会让部分客户端节点的行为与其他客户端不一致,对Geth客户端运行者来说很不公平。上述话题随即引发了关于以太坊路线图中存储方案的激烈讨论。
下面的饼图展示了截至2023 年 12 月 13 日时,区块高度为18,779,761下,一个新 Geth 节点的存储分布情况:
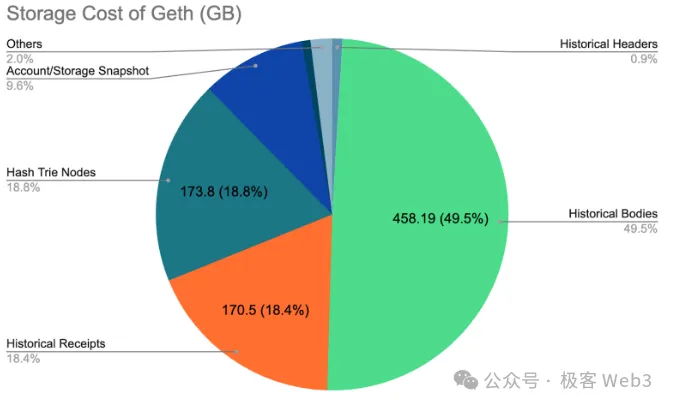
- 总存储大小:925.39 GB
- 历史数据(区块/交易收据):约 628.69 GB
- Merkle Patricia Trie (MPT) 中的状态数据:约 269.74 G
当存储成本成为节点的重大负担时,一些节点运营商选择删除历史数据就不足为奇。在没有历史数据的情况下,节点客户端可以显著降低存储成本,将占用的存储空间从大约 1TB 减少到 300GB 左右。
客户端运行者可以自由地删除或修改所有历史数据,而不会受到任何惩罚。相比之下,Validator节点必须在本地维护并更新完整的状态,以防止因提议/投票支持无效区块而被Slash(安全和惩罚机制)。
主要问题:
- 以太坊客户端的存储要求变多越来越高(数据量越来越大)
- 存储以太坊历史数据没有任何的协议内的激励或者惩罚
未来的挑战
随着即将到来的以太坊数据可用性(DA)升级,存储挑战将会加剧。全面扩容以太坊 DA 的道路始于 DenCun 升级中的 EIP-4844,它引入了一个固定大小的二进制大对象 (BLOB) ,和一个被称为 blobGasPrice 的独立费用模型。每个 BLOB 设置为 128KB,EIP-4844 实行后,每个区块最多包含6个BLOB。为了对数据吞吐量进行扩容,以太坊计划采用 1D Reed-Solomon 纠删码,最初允许每个区块有 32 个 BLOB,并在完全扩容时达到每个区块 256 个 BLOB 的量级(逐步升级中)。
如果以太坊 DA 以全容量运行(每个块 256 个 BLOB),以太坊 DA 网络预计一年将接收大约 80 TB 的DA数据,该数字远远超出大多数节点的存储能力。
即随着以太坊节点的数据量越来越大,存储成本越来越高,可能会有更多的客户端选择删除以太坊的某些历史数据(历史区块)。
删除历史数据的后果
不断上升的存储成本引起了以太坊生态研究人员的关注。为了解决这个问题并确保所有客户端的一致性,研究人员正在制定一些提案来明确删除以太坊客户端的历史数据。两个主要提案是:
· EIP-4444:限制执行客户端中的历史数据:该提案允许客户端删除超过一年的过往区块。假设平均区块大小为 100K,历史块数据上限约为 250 GB(100K (3600 24 * 365) / 12,假设区块时间 = 12 秒)。
· EIP-4844:分片 BLOB 交易:丢弃超过 18 天的 BLOB数据。与 EIP-4444 相比,这是一种更激进的方法,将历史 BLOB 大小限制在 100 GB 左右((18 3600 24) 128K 6 / 12,假设区块时间 = 12 秒)。
删除所有客户端的历史数据会产生什么后果?主要的一个问题是,新节点无法通过“full sync”模式来同步到最新状态, “full sync”是一种将历史数据重放,从创世区块同步到最新区块的数据同步方案。相应地,我们必须采取“snap sync”或“state sync”来直接同步以太坊节点的最新状态。这种方法已在 Geth 中实现,并作为默认的同步运行方式。
节点删除掉以太坊主网历史数据,也会导致以太坊 L2出现问题,即新加入的Layer2节点,无法通过重放 Layer2全部历史数据的方法,同步至当前的最新状态。此外,由于 L1 节点不维护 L2 状态,L2 的“snap sync”方法无法根据Layer1区块直接派生出最新的 Layer2 状态,这违反了Layer2继承以太坊安全所需的重要假设。
以太坊需要有一个存储层,而且是一个去中心化的、不需要对以太坊本身的协议进行升级的一个存储层,或者我们叫模块化的存储层来解决数据的长期保存问题。
去中心存储概述
随着Web3的发展,越来越多属于Web3的数据被挖掘和产生,而这些数据往往被存储在web2的中心化的存储平台上,但是这往往会带来额外的问题,例如中心化服务器的崩溃导致数据丢失,数据审查等问题。
因此去中心化存储也孕育而生,跟中心化存储不同的是,提供数据存储服务的数据节点网络,是通过p2p网络进行网络通信和数据同步的,并且任何人都可以无许可( permissionless )的加入这个网络,成为网络中的一个数据节点 。
从用户端而言,任何用户都可以无许可地存储任何你想存储的数据,只要为数据支付相应的存储费用;最终存储的数据会以多个副本的形式保存在网络内,因此也基本上避免了数据丢失的可能性(容灾性好)。
读取数据的时候,用户的读取请求会由p2p网络进行转发,最终存储了该数据的数据节点会响应该读取请求
设计去中心化存储需要考虑的几个问题:
- 一个节点如何高效地证明它完整的存储了一个数据分片的数据?
- 如何给节点发放存储奖励?
- 在这个系统下,怎么保证存储的数据不丢失?或者说怎么保证这份数据有足够保证安全的副本数量?
- 如何让每份数据的副本数量基本保持一致?
- 收费标准
EthStorage网络
官网:https://eth-store.w3eth.io/#/
EthStorage: https://file.w3q.w3q-g.w3link.io/0x67d0481cc9c2e9dad2987e58a365aae977dcb8da/dynamic_data_sharding_0_1_6.pdf
EthStorage存储流程和原理:https://ethstorage-cn.medium.com/ethstorage-%E7%AC%AC%E4%B8%80%E4%B8%AAethereum%E5%AD%98%E5%82%A8l2-306aaca6569b
概述
一个无需许可的去中心化的Layer2数据存储网络。支持通过部署在以太坊主网合约上对存储的数据进行完整的CRUD,支持PB级别的数据存储。
优势:
- 丰富的存储语义(KV CRUD)。 FILECOIN/AR 主要适用于静态文件,缺乏高效的更新/删除操作 — — 即,用户必须支付两次费用才能更新现有数据。而得益于数据可用(DA)和智能合约,EthStorage 可以提供类似于 SSTORE 的完整 KV CRUD 语义。
- 可编程性。存储可以通过智能合约进行编程,这便可以很容易的启用新功能,例如多用户访问控制或数据可组合性。
我们的早期分析表明,与通过 SSTORE 操作码完全复制的 EVM 原生 KV 存储相比,存储大值的成本可以降低至约 1/100 倍,同时确保网络中存在数十或数百个值的副本。 --- Decentralized Storage on Large Dynamic Datasets with Applications for Large Decentralized KV Store。
基本架构
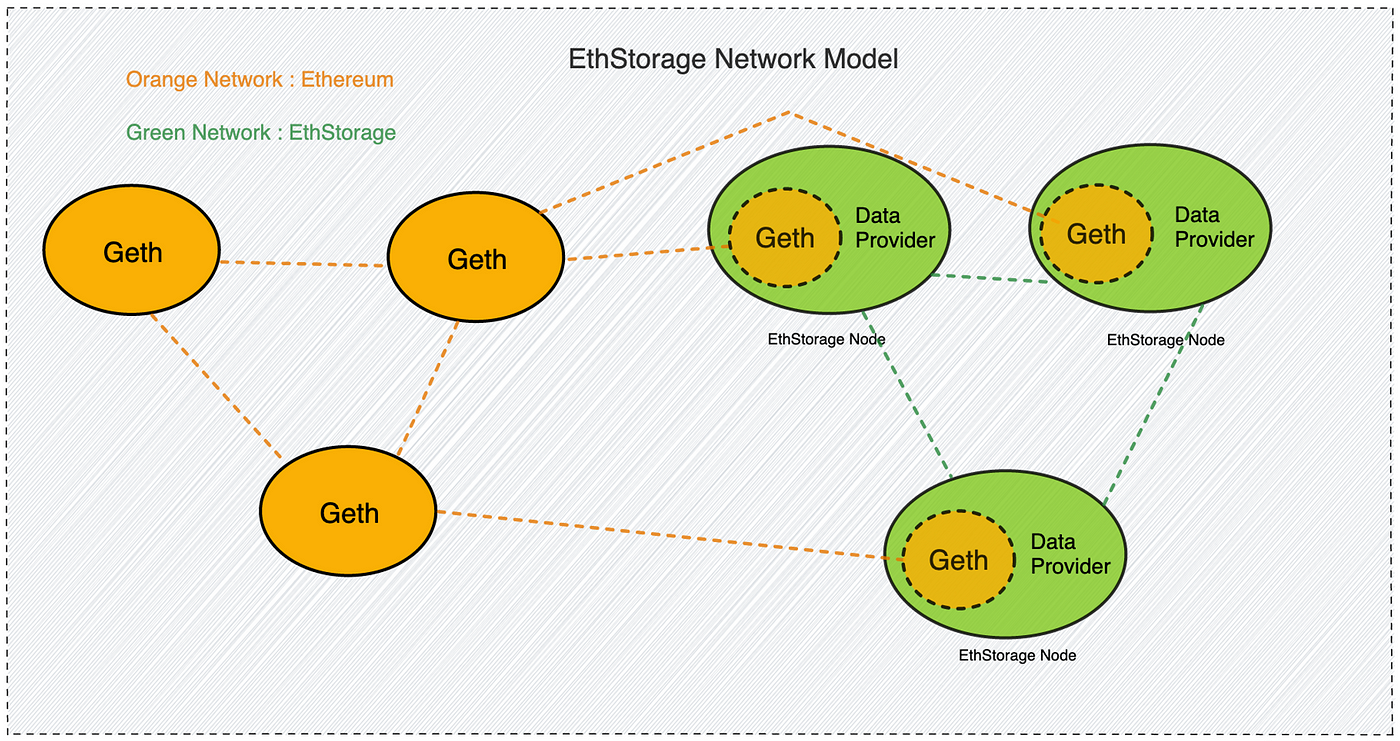
EthStorage 的客户端是以太坊客户端 Geth的超集,这运行EthStorage的节点的时候,依然可以正常参与以太坊的任何流程。
当启动一个EthStorage Node的时候,实际上是运行着一个 Geth 和 Data Provider 的结合体,内部运行的 Geth 可以保证节点正常参与以太坊网络,例如,一个节点可以是以太坊的验证者节点的同时也是EthStorage的数据节点。
每个 EthStorage Node 的 Data Provider 模块会跟其他 EthStorage Node 的 Data Provider 发起建立连接请求,当它们互相连接之后,实际上就构成了一个去中心化存储网络。
橙色网络代表去中心化的以太坊网络,绿色网络代表由EthStorage支持的去中心化存储网络。
CRUD
EthStorage在以太坊主网上部署有智能合约来支持CRUD
contract DecentralizedKV {
function put(bytes32 key, bytes memory data) public payable {
...
}
function get(
bytes32 key,
uint256 off,
uint256 len
) public view returns (bytes memory) {
...
}
function remove(bytes32 key) public {
...
}
function verify(
bytes32 key,
bytes memory data
) public view returns (bool){
...
}
}
- put : 这是一个写数据的方法(新增或者更新),调用这个方法会将给定的数据 (data) 存储在我们对应的数据分片(shard)中,并且你可以在读取方法中通过对应的 key 读到它。
- get : 这是一个查询方法,调用这个方法可以进行获取要查询的 key 的对应数据。
- remove : 这是一个删除数据的方法,调用这个方法可以会删除key对应的数据。
- verify: 这是一个验证方法,可以检查分片(shard)中存储的数据的数据哈希是否是跟合约内的数据哈希匹配,如果匹配证明链下存储的数据是正确的。
Put(增)
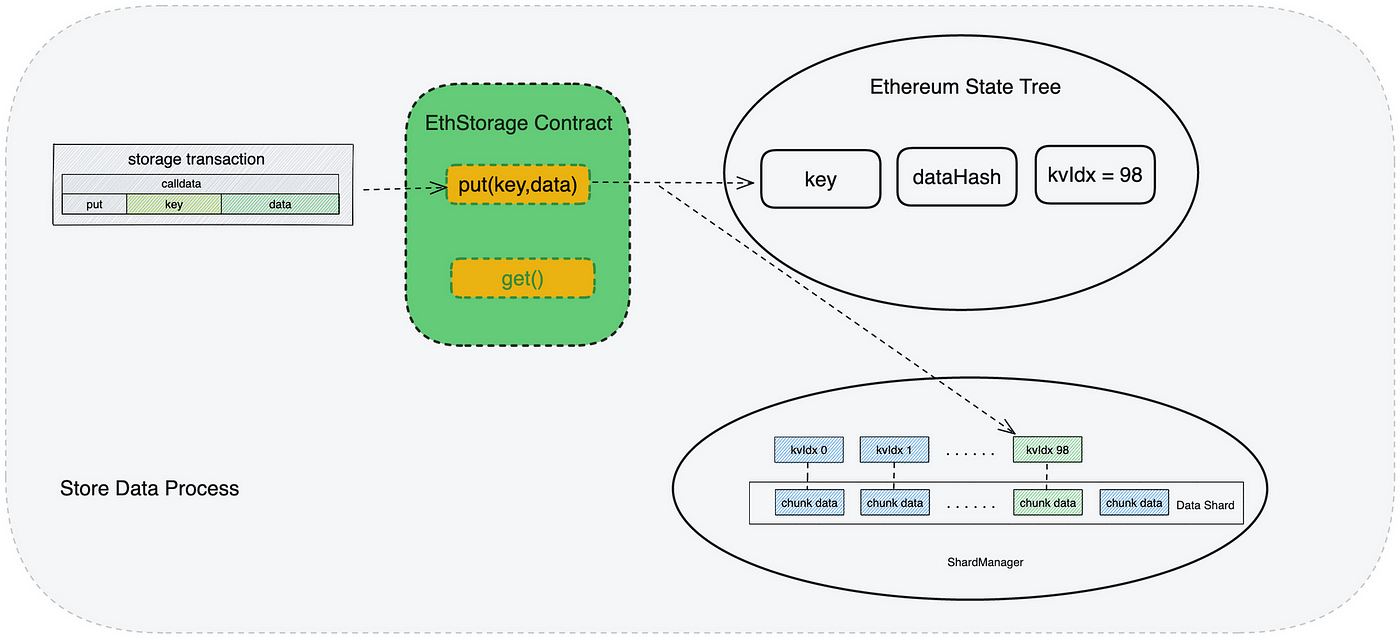
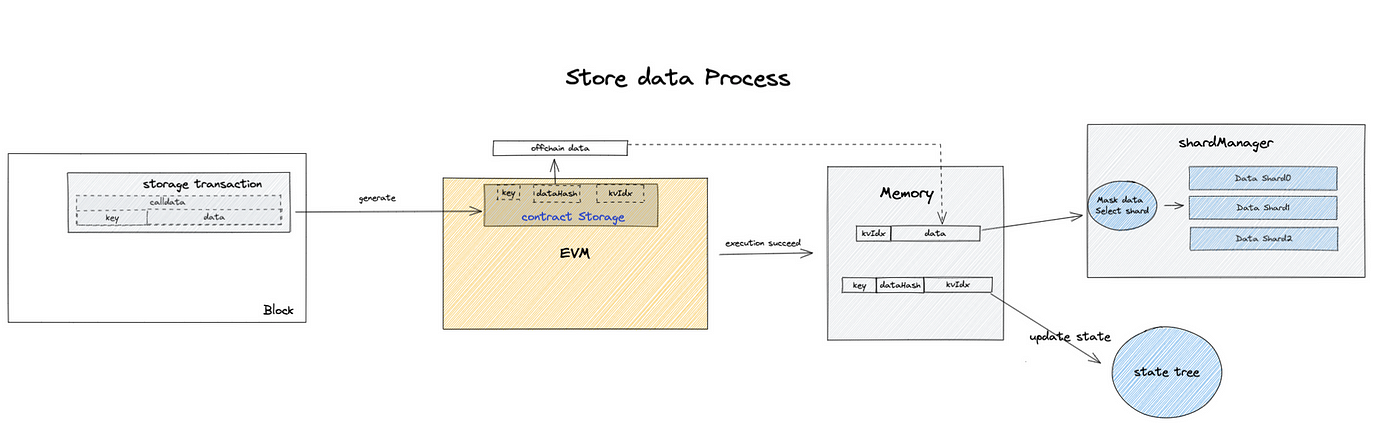
保存数据到EthStorage是通过调用合约中的put(bytes32 key, bytes memory data)方法进行的,当用户填写key和data之后,发起一笔以太坊交易,合约执行回计算dataHash和keyIdx,并将dataHash和keyIdx进行保存,当EthStorage的客户端ShardManager坚挺到有新的Put交易发生,将会根据keyIdx将data保存到对应的数据分片中。
Put(改)
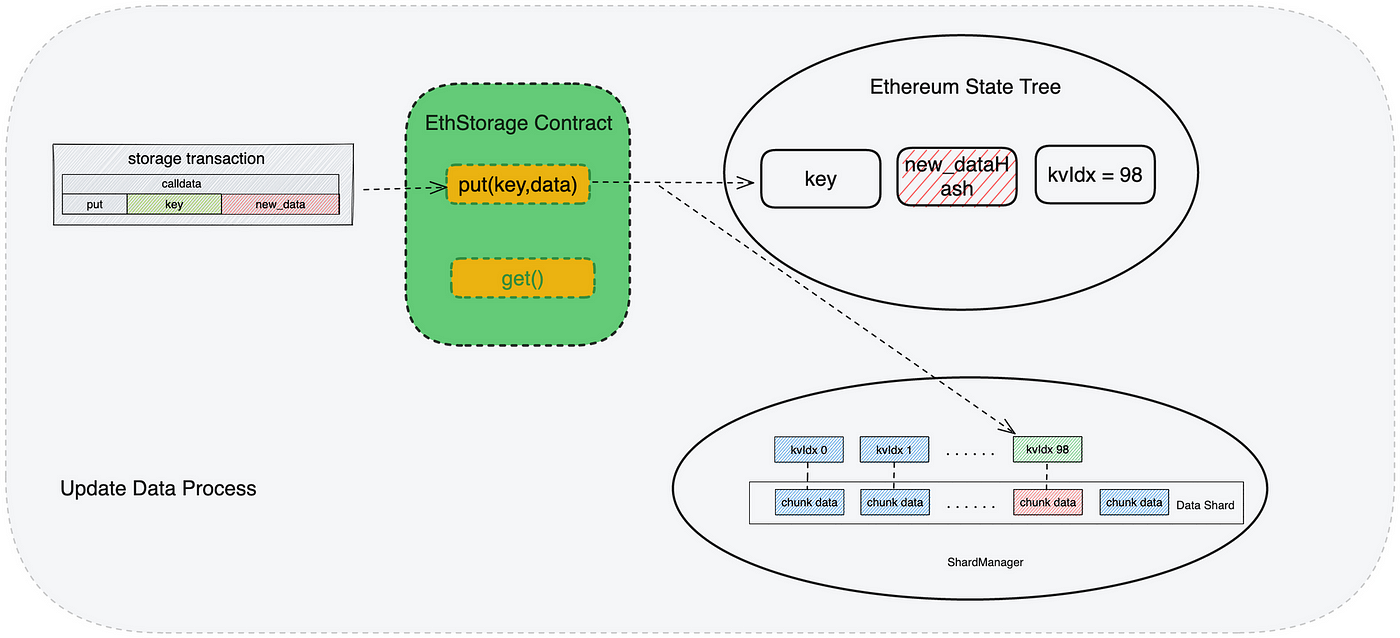
当用户需要更新存储在 EthStorage上的数据的时候,通过发起一笔以太坊调用合约的交易,来执行 put 方法:
● 调用方法put( key , new_data ):
key: 用户之前存储数据对应的key
new_data: 用户希望存储的新数据
● 更新数据的执行流程跟存储数据流程基本差不多,具体如下:
- 用户发起一笔调用合约put方法的交易: submit Tx{ put( key , new_data ) };
- 这笔交易会将记录在合约中对应的key的哈希更新: dataHash = hash(new_data);
- EthStorage客户端 的 ShardManager 监听到有新的 put 交易发生,获取到 put方法中携带的要更新的数据 new_data;
- ShardManager 将要更新的数据进行mask(密封)之后替换之前存储的数据;store( kvIdx , mask(new_data))
图中标注为红色方格的数据,是update过程中被修改的数据。
Get
调用 get(key) ,可以通过key找到对应的kvIdx,然后根据kvIdx向数据节点发送读取请求,数据节点判断该kvIdx对应的数据是刚好在自己存储的数据分片中的时候,会向用户回复请求的数据;如果矿工没有存储对应数据,则会帮助用户转发读取数据的请求。
Remove
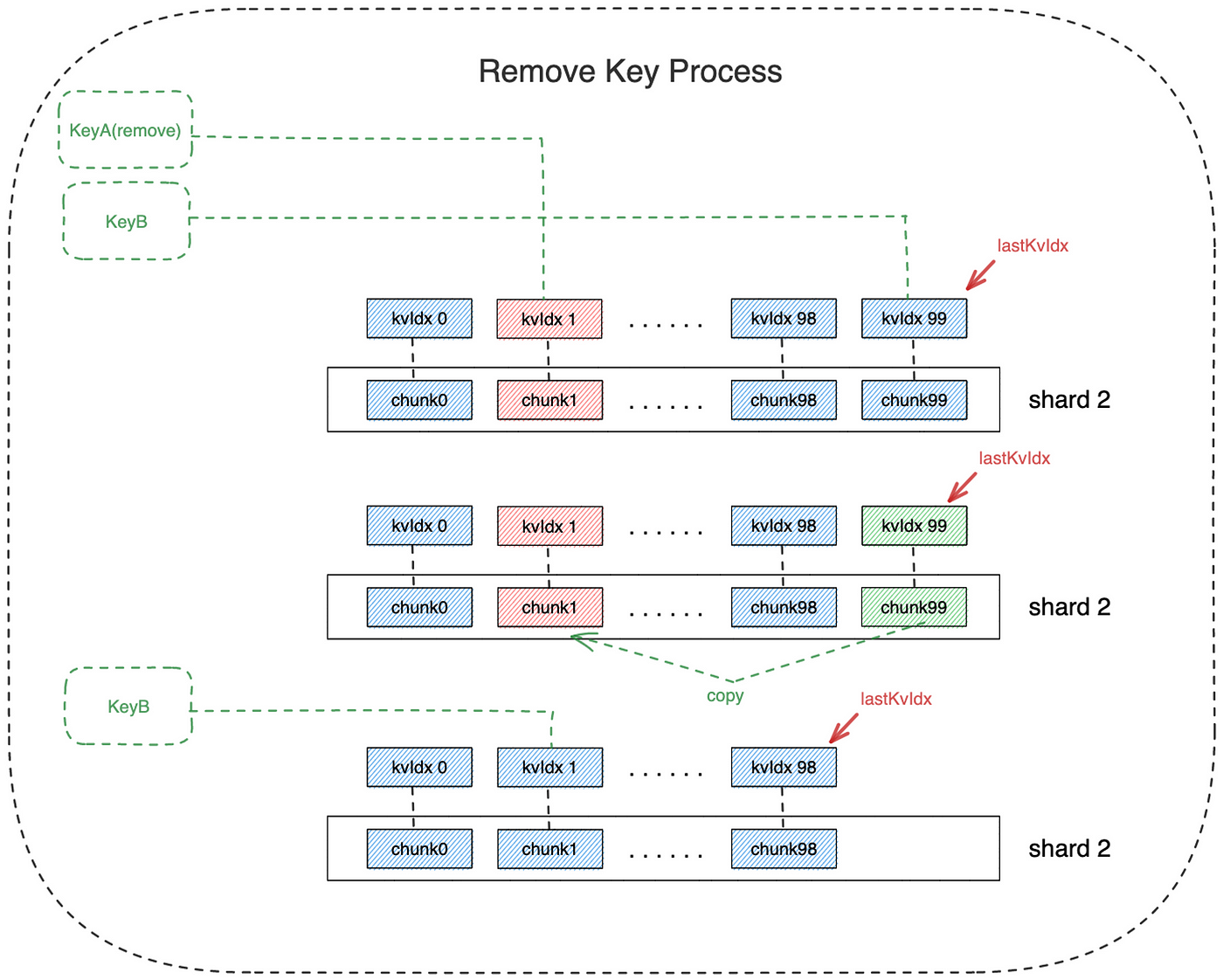
假如:KeyA 对应的kvIdx为1 ,用户此时要将KeyA对应的数据移除;当前最大的kvIdx对应的键为KeyB
● 调用方法:remove(key)
- key: 你想要删除数据的索引key
● 删除步骤:
- 发起一笔调用remove方法的交易: submit Tx{ remove(KeyA) };
- ShardManager 将KeyB对应的数据读出来之后,复制到KeyA的数据存储位置: copy(chunkIdx(KeyA), readMasked(keyB));
- ShardManager 将KeyB的数据( chunk99 )删除: delete(chunk99);
- 合约 将 KeyB 对应的 kvIdx 从 99 改为 1: updateKvIdx(KeyB, 1);
- 合约 将 lastKVIdx 由 99 改为 98: lastKvIdx =lastKvIdx — 1;
verify
核心原理是 EthStorage 会在合约内记录 key 所对应数据的哈希,在每次进行随机访问证明(Proof-of-Random-Access) 的时候会将矿工上传的数据进行哈希,然后与合约内存储的数据数据哈希进行验证,只有合约内存储的数据哈希和上传的数据哈希相等,随机访问证明才会生成一个有效的证明。
激励机制
随机访问证明(roof-of-Random-Access)
可用证明它完整的存储了一个数据分片的数据
问题:存储费用怎么收取, ETH?
当调用 put() 方法时,交易必须发送存储费(通过 msg.value)并存入合约中。在成功链下存储节点提交并验证存储证明后,这个存储费用将随着时间的推移逐渐分配给存储节点。
如果对普通的geth执行get
以太坊 Portal Network
官网的FAQ: https://www.ethportal.net/resources/faq
Portal Network 标准:https://github.com/ethereum/portal-network-specs
简单介绍:https://ethereum.org/zh/developers/docs/networking-layer/portal-network/
概述
以太坊用户有两种选择:
- 投入大量的计算资源和带宽来运行以太坊节点(存储成本高)
- 信任中心化第三方(例如 RPC 提供商)来提供以太坊数据(可能需要收取费用)
Portal Network 为以太坊用户引入了第三种选择:
- 以分散的方式访问以太坊数据,且硬件和带宽要求最低(手机或 Raspberry Pi 设备也有可能加入该网络)。
Portal Network是一种与以太坊并行运行的点对点协议。以太坊数据分布在整个门户网络中,而不是在每个单独的节点中复制。这使得用户能够以最少的硬件和带宽要求访问以太坊数据,并且几乎可以即时同步。
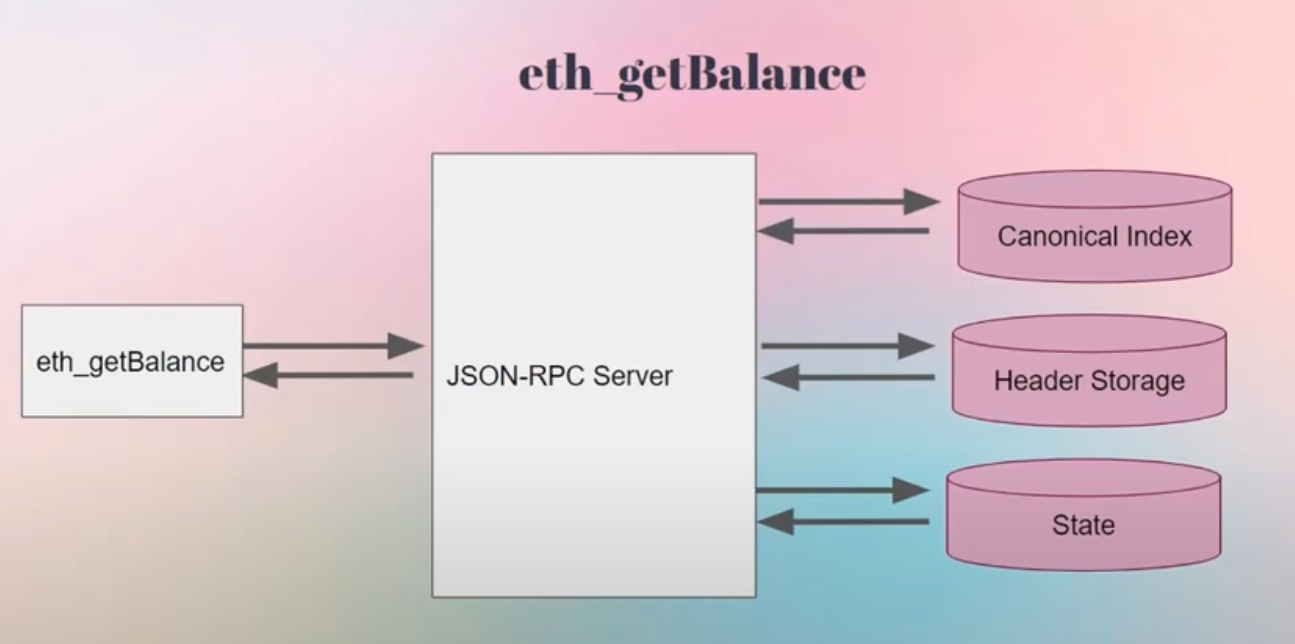
传统方式:
protal network
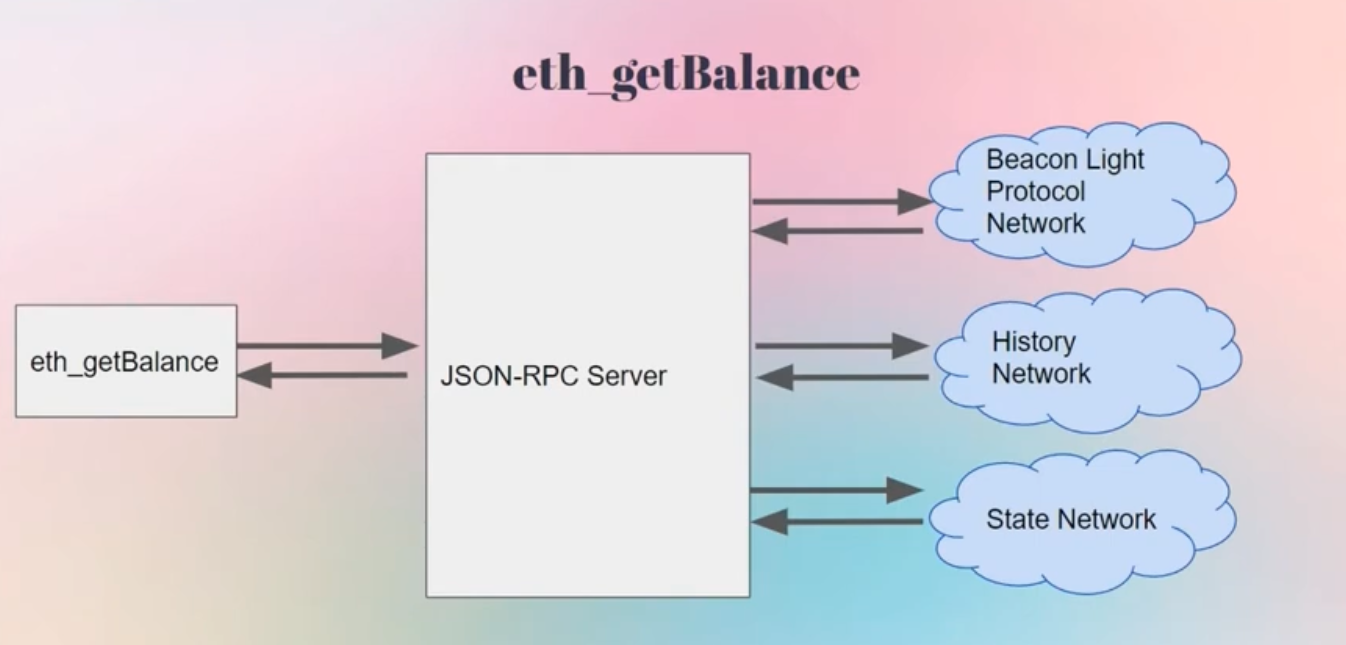
Portal Network 实际上是几个可以使用 Portal Network客户端访问的点对点网络(状态网络、信标网络和历史网络)。
每个网络都存储以太坊全节点存储的数据的特定子集。每个门户客户端仅存储每种类型数据的一小部分。然而,门户网络(完整的节点集)存储了从创世一直到链头的一两个区块内的所有历史以太坊数据。
当从 Portal 节点请求数据时,该请求会在网络上从对等点广播到对等点,直到它最终到达存储您想要的特定信息的节点。然后该节点将响应返回给您。没有中介机构,也没有中心化的参与者需要存储大量的链上数据或处理大量的请求。
存储方式??分布式存储,kademlia DHT
激励机制??无,利己,为资源匮乏的用户提供获取全链数据
目前无法执行交易,没有实现对应的JSON RPC接口,可以查看https://github.com/ethereum/portal-network-specs 中描述了实现的JSON RPC接口
为什么不是使用轻客户端通过对以太坊全节点的 RPC 调用获取数据?很少有节点运营商仅仅出于利他的原因这样做,数据是需要收费的。
问题
一个节点如何高效地证明它完整的存储了一个数据分片的数据?
怎么保证存储的数据不丢失?或者说怎么保证这份数据有足够保证安全的副本数量?
可能需要看源码
目前所有的Portal Network还无法上生产
Celestia Blobstream
https://docs.celestia.org/developers/blobstream
作为Layer2的DA
参考资料
以太坊存储方案路线图:挑战与机遇共存:https://mp.weixin.qq.com/s/eDown8DF6w9bKfqP_URS0w
对话 EthStorage 创始人 Qi Zhou | 数据可用性和去中心化存储:https://learnblockchain.cn/article/6216
EthStorage官网:https://eth-store.w3eth.io/#/
EthStorage: https://file.w3q.w3q-g.w3link.io/0x67d0481cc9c2e9dad2987e58a365aae977dcb8da/dynamic_data_sharding_0_1_6.pdf
EthStorage存储流程和原理:https://ethstorage-cn.medium.com/ethstorage-%E7%AC%AC%E4%B8%80%E4%B8%AAethereum%E5%AD%98%E5%82%A8l2-306aaca6569b
Portal Network官网:https://www.ethportal.net/
Portal Network官网的FAQ: https://www.ethportal.net/resources/faq
Portal Network 标准:https://github.com/ethereum/portal-network-specs
Portal Network简单介绍:https://ethereum.org/zh/developers/docs/networking-layer/portal-network/
Portal Network简单视频介绍:https://www.youtube.com/watch?v=0stc9jnQLXA