Scroll整体架构和主要流程
官方文档:https://docs.scroll.io/zh/technology/
Scroll主要有两个功能:跨链桥和rollup
跨链桥:用于以太坊和Scroll之间发送消息和资产,主要负责L1和L2进行通信,可以在L1上调用L2的合约,也可以在L2上调用L1的合约。
rollup: 用于保证L2上的数据与L1上的数据拥有一样安全性,保证L2数据的可用性(Data Avaliability)和验证有效性证明(Proof Verification)
采用zkRollup实现以太坊扩容的优势:
以单笔交易代替了很多笔交易
增加了交易吞吐量
节约了手续费
降低了延迟等待
Scroll zkEVM与以太坊主网EVM兼容,可将以太坊主网的智能合约部署在Scroll zkEVM中,可共用以太坊现有的开发组件和套件。
整体架构
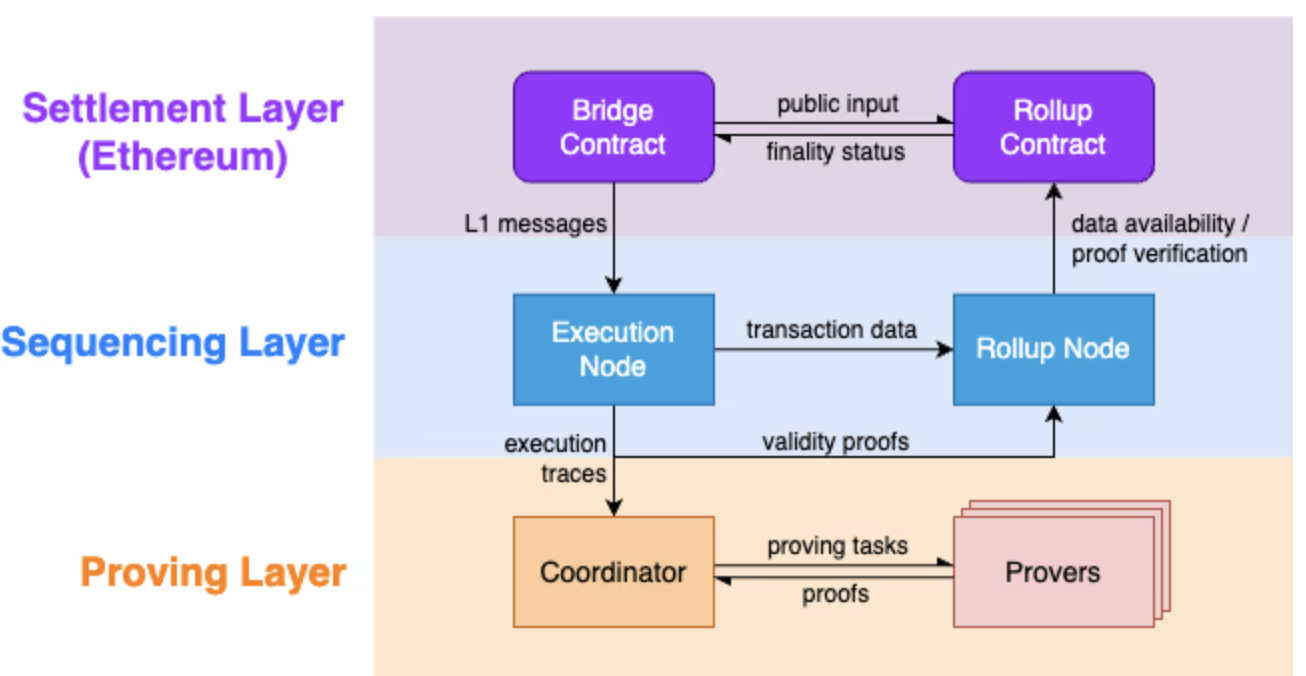
如上图所示,Scroll 链由三层组成:
- 结算层(Settlement Layer): BridgeContract 主要用于用户和去中心化应用程序在以太坊和Scroll之间发送消息和资产。RollupContract主要是用于提供数据可用性和验证有效性证明。我们使用以太坊作为结算层,并将跨链桥和Rollup合约部署到以太坊上。
- 排序层(Sequencing Layer): 包含一个Execution Node以及一个Rollup Node,Execution Node用于执行提交到 Scroll 排序器的交易和提交给 L1 跨链桥合约的交易并生成 L2 区块,Rollup Node用于批处理交易,将交易数据和区块信息发布到以太坊以获得数据可用性,并将有效性证明提交给以太坊以进行最终确认。
- 证明层(Proving Layer): 由一个证明器池组成,这些证明器负责生成验证 L2 交易正确性的 zkEVM 有效性证明,以及一个协调器,将证明任务分配给证明器并将证明中继到Rollup节点以在以太坊上最终确认。
主要流程
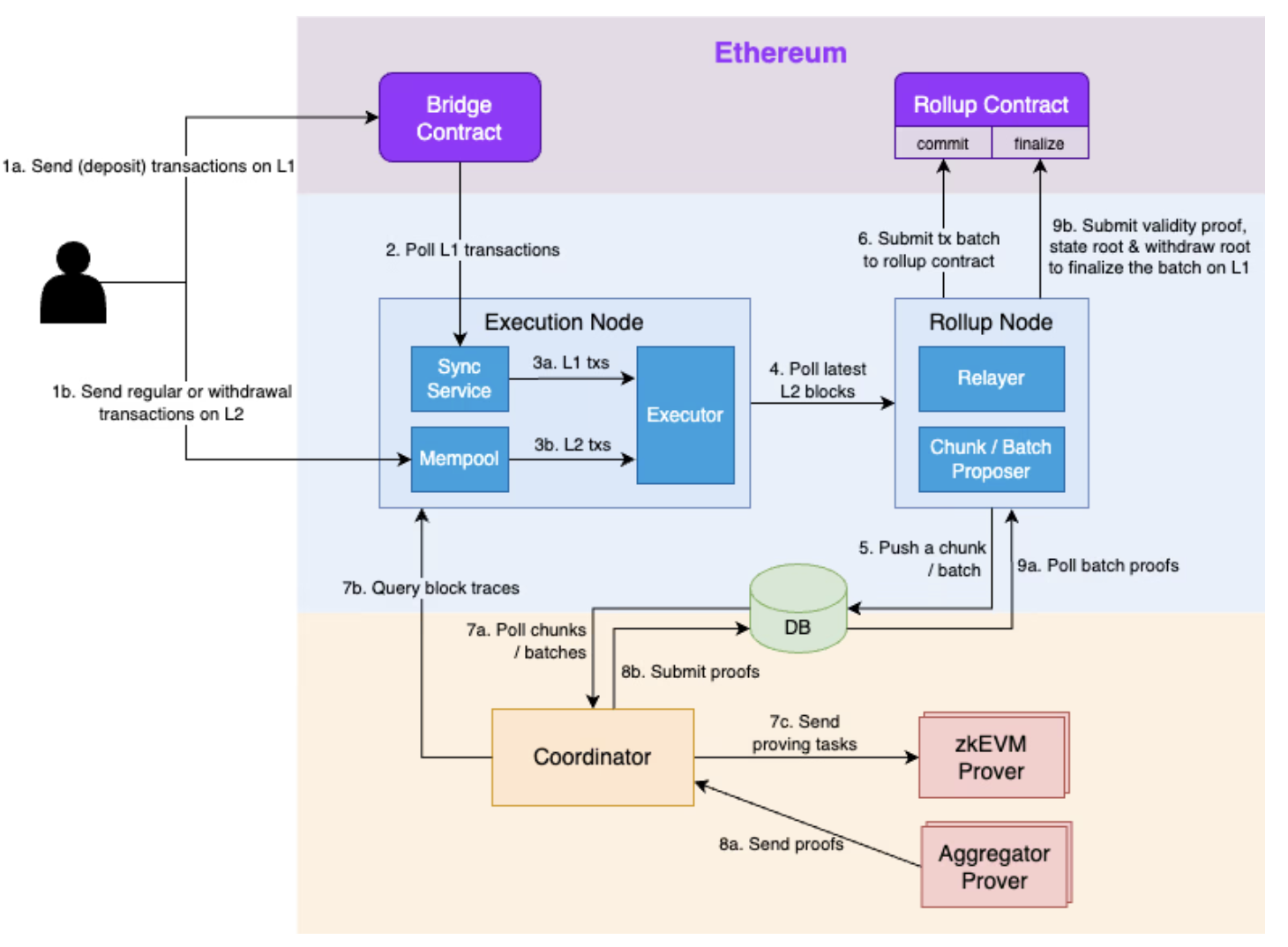
Scroll主要流程分为三个阶段:
1)交易执行 (上图步骤1.a、1.b、1.c、2、3a、3b)
2)批处理和数据承诺(上图步骤4、5、6)
2)证明生成和最终确认(上图步骤7a、7b、7c、8a、8b、9a、9b)
L2的交易有两个来源:
1)L2通过订阅L1跨链桥合约的交易
2)直接发送到L2的交易
Execution Node
L2的排序器包含三个模块:Sync service、Mempool、Executor
Sync Service(同步服务):L2通过订阅提交到L1跨链桥合约中的交易,一旦检测到,L2同步服务将对应的生成一个L1MessageTx交易(L2链上根据EIP-2718定义的新的交易类型),并将其添加到本地L1交易队列。
MemoryPool(内存池):直接提交到L2排序器的交易将会被放在MemoryPool中。
Executor(执行器):从L1交易队列和L2内存池中提取交易,执行交易并构建新的L2区块。
Rollup Node
Roll节点包含三个模块:Relayer、Chunk Proposer、Batch Proposer
Relayer(中继器): 提交承诺交易(Data Avaliability)并在rollup合约中最终确认(Proof Verification)。
Chunk Proposer(块提议者)和Batch Proposer(批次提议者)会按照下面的规则提议新块和新批次:

Rollup节点收集新的L2区块并将其打包成块(chunks)和批次(Batches)。一组排序好的交易会被打包成一个块;一系列相邻的区块将会被分组进入一个块(chunk)中(chunk是生成zkEVm电路证明的基本单元);一系列相邻的chunk被分组到一个批次(batch)中,批次是L1上数据承诺(Data Avaliability)和证明验证(Proof Verification)的基础单元,批次证明是从批次中区块证明的聚合证明。
一旦chunk被创建,就会将chunk对应的task发送的zkevm证明器,生成其证明。
阶段1:交易执行
- 用户将交易提交到L1跨链桥合约或者L2的Execution Node,提交到L2的交易将会被放入到Execution Node的Memory Pool中。(上图步骤1a、1b)
- L2 Execution Node中的sync service从跨链桥合约中提取最新L1交易,并放入到本地的消息队列。(上图步骤2)
- L2 Execution Node的Executor从本地的L1消息队列和Memory pool中获取交易,并构建新的L2区块。(上图步骤3a、3b)
阶段2:批处理和数据承诺
- Rollup Node监听Execution Node的产生的最新区块。(上图步骤4)
- 如果满足条件,Rollup Nod将提议一个新的chunk或者batch并写入数据库,否则Rollup Node会等待更多的block或者chunk来创建新的batch(上图步骤5)。
- 创建了新的batch之后,Rollup Relayer将收集此batch中的transaction数据,并将承诺交易提交到Rollup合约来实现数据可用性(Data Avaliability)。(上图步骤6)。
阶段3:证明生成和最终确认
- Coordinator(协调器)会轮询数据库,一旦查询到新的chunk或者batch。将会执行以下操作:(上图步骤7a、7b、7c)
- 在新的chunk上,Coordinator将会从L2 Execution Node中查询当前chunk中所有block的执行轨迹(execution traces),然后将证明任务发送到随机选择的zkEVM证明器(zkEVM Prover)。
- 在新batch上,Coordinator将会从数据库中收集当前batch中所有chunk的chunk证明,并将batch证明任务分配给随机选择的聚合证明器。
- 当Coordinator从zkEvm Prover获取到chunk或者batch的证明时,Coordinator会将证明写入到数据库。(上图步骤8a、8b)
- 一旦Rollup Node中的Ralyer从数据库中轮训得到新的batch的证明,它就会想Rollup合约提交最终确认交易来验证证明(Proof Verification)。(上图步骤9a、9b)
交易的生命周期
Scroll中的交易的生命周期包含三个阶段:
- 已确认(Confirmed): 用户向L1跨链网桥合约或者L2 Execution Node提交交易,交易执行并包含在L2区块中后变为Confirmed。
- 已提交(Committed): 交易被包含在batch中,并且包含此batch数据的承诺交易(commit transaction)已经被提交到L1,在L1区块中确认承诺事务后,此batch中的交易变为Committed。
- 最终确认(Finalized): 该batch的证明生成并在L1上得到验证,在最终确认交易(finalize transaction)在L1上最终确认后,该batch中的交易状态变为Finalized。
问题:
Sequencing Layer和Proving Layer是否是去中心化的,是否需要去中心化?https://foresightnews.pro/article/detail/35169
有无激励机制?